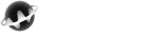Root Cause in Seconds, Not Hours
See exactly what broke, when it broke, and why - with ML that thinks in microseconds and AI that speaks your language. From alert to resolution in 5 minutes instead of 75.

See exactly what broke, when it broke, and why - with ML that thinks in microseconds and AI that speaks your language. From alert to resolution in 5 minutes instead of 75.
Six capabilities that redefine how fast you find and fix problems
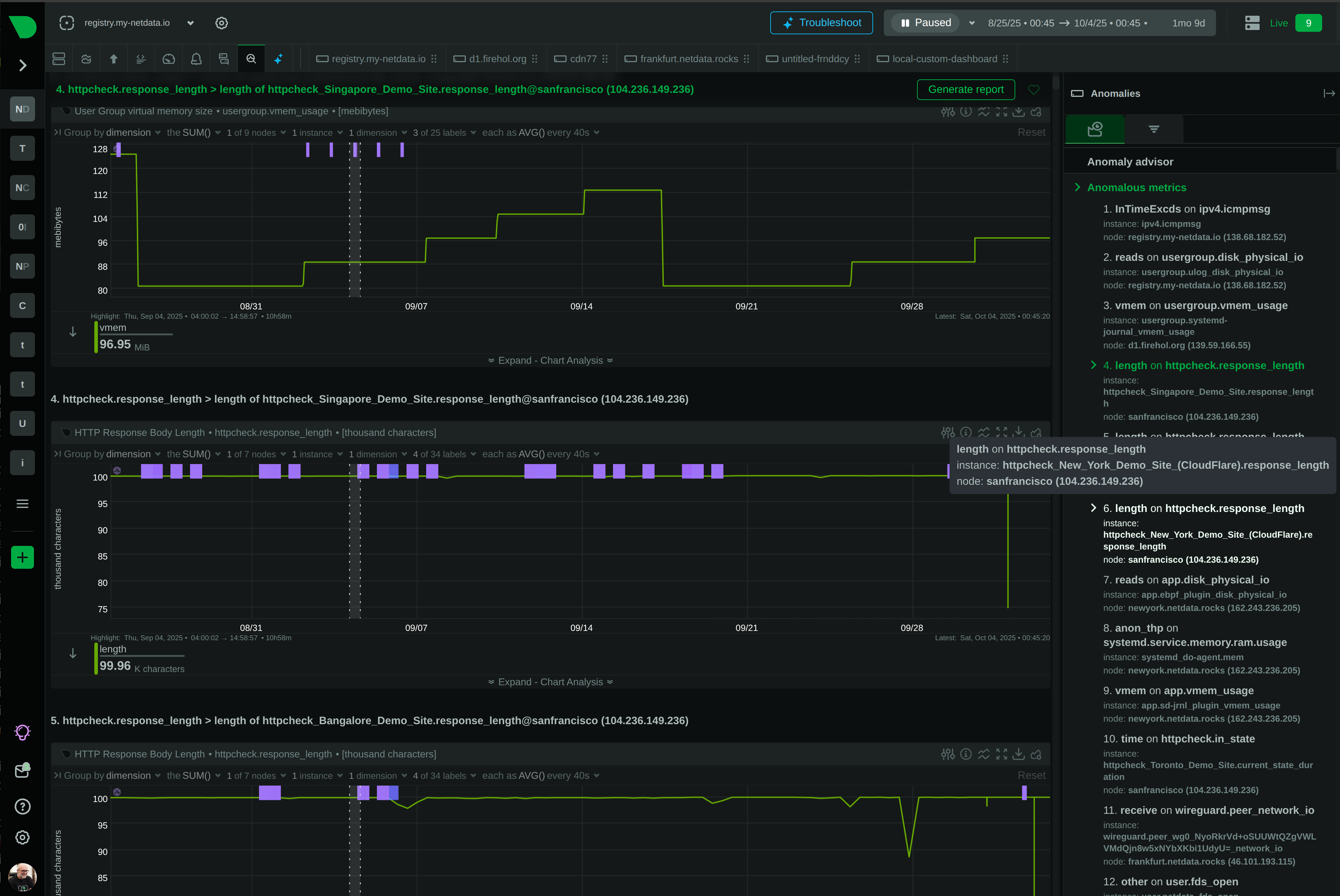
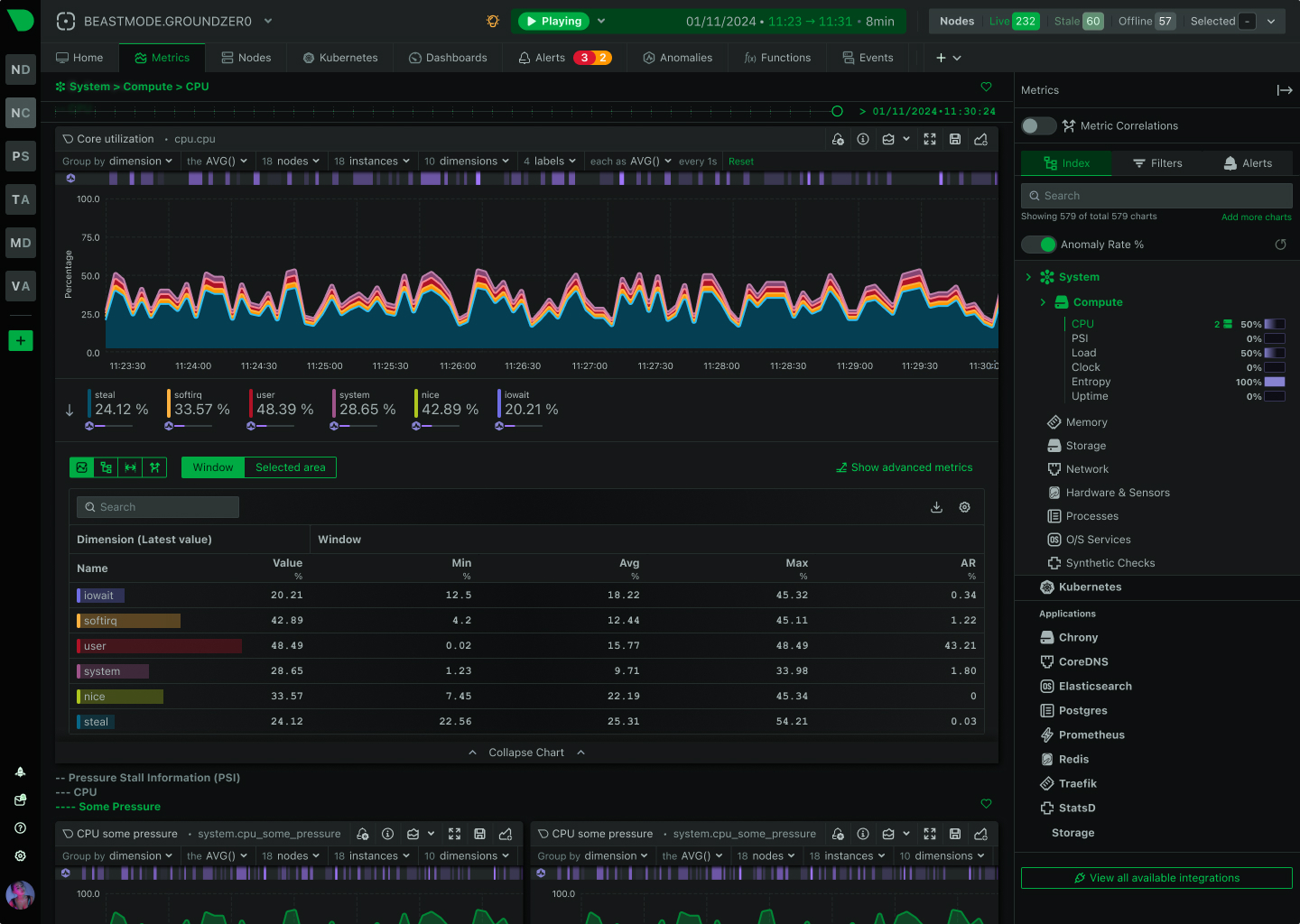
18 ML models per metric detect problems as they happen - no waiting for batch processing or manual threshold tuning.
Evaluate thousands of metrics in seconds, surfacing root cause in the top 30-50 results - no manual dashboard hunting.
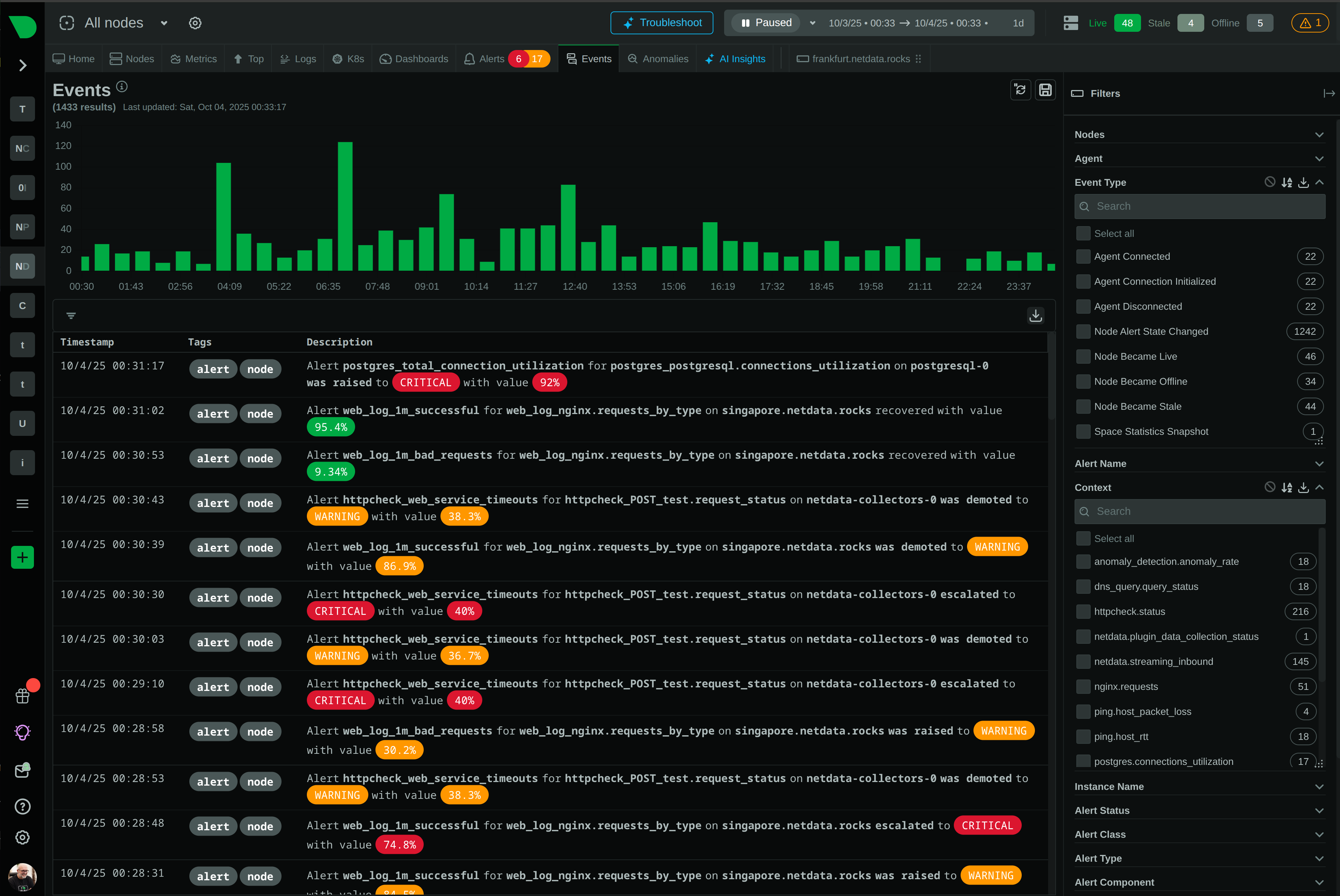
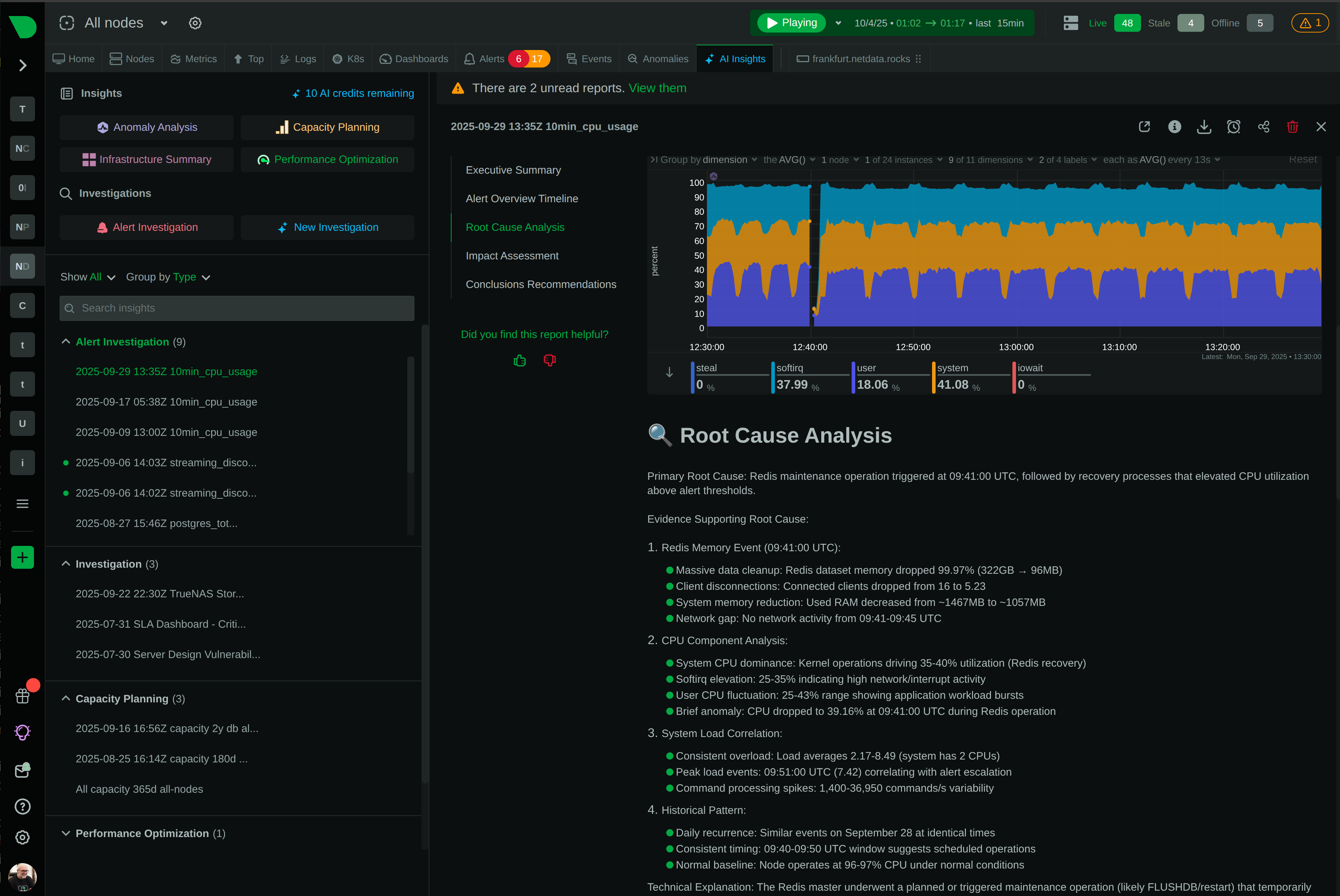
Get complete RCA reports in 2 minutes with hypothesis, evidence, and recommendations - in plain English.
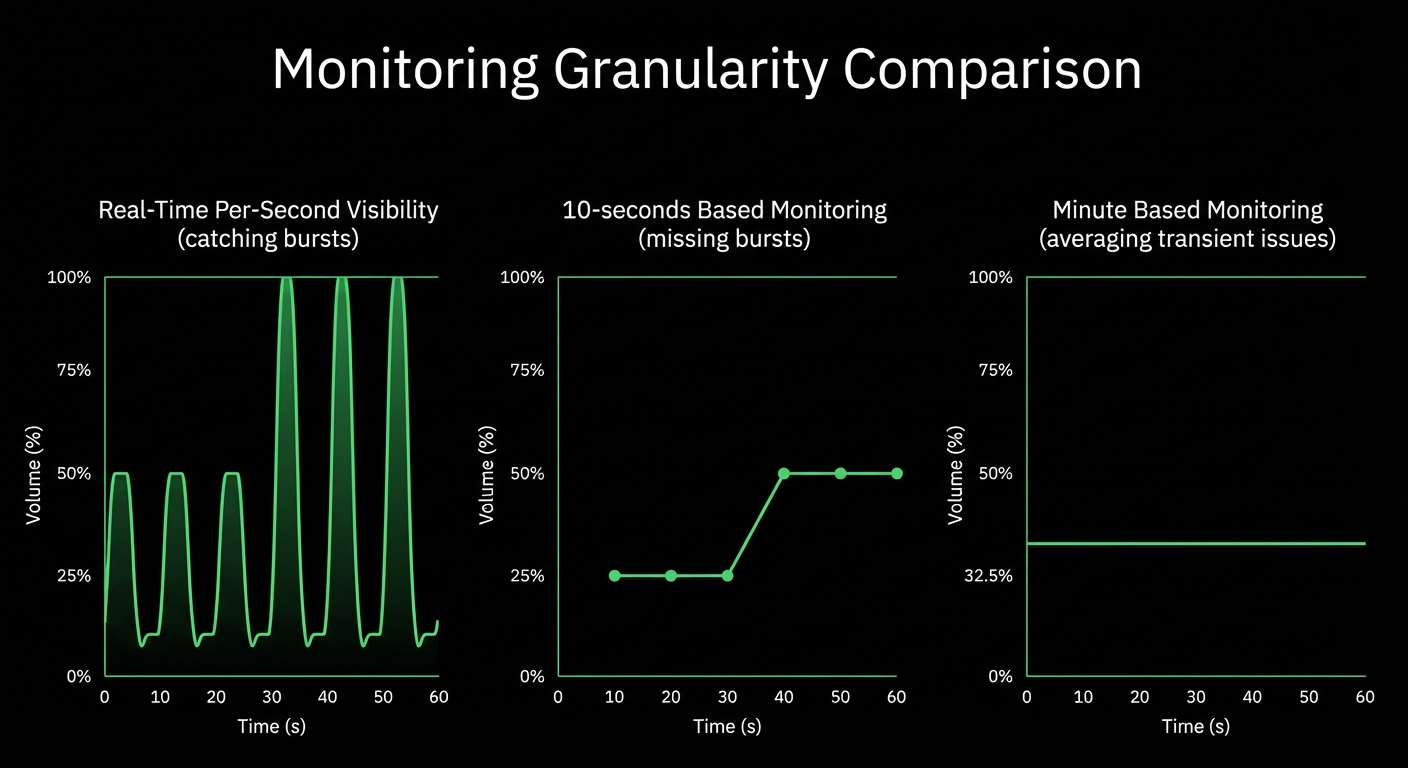
Capture transient failures that 30-second monitoring misses entirely - see the 3-second events that break systems.
Watch failures propagate in real-time across distributed infrastructure - identify which component failed first.
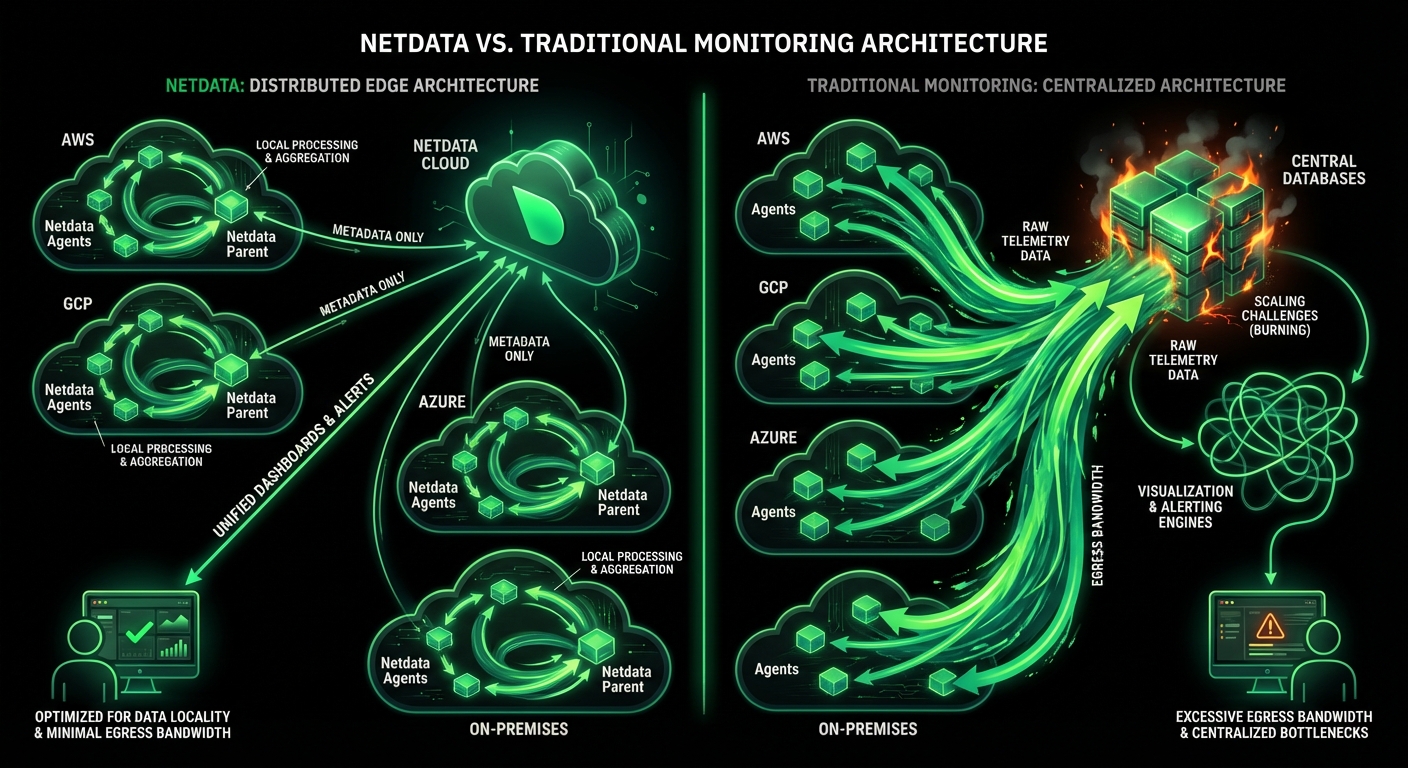
Per-node pricing eliminates volume anxiety - unlimited metrics, logs, and users at 90% lower cost.
Trusted by DevOps teams worldwide
86,400 samples/day per metric vs 2,880 for 30-second monitoring
Learn about real-time monitoring
80% MTTR reduction - from 75 minutes to 5 minutes
Explore Anomaly Advisor
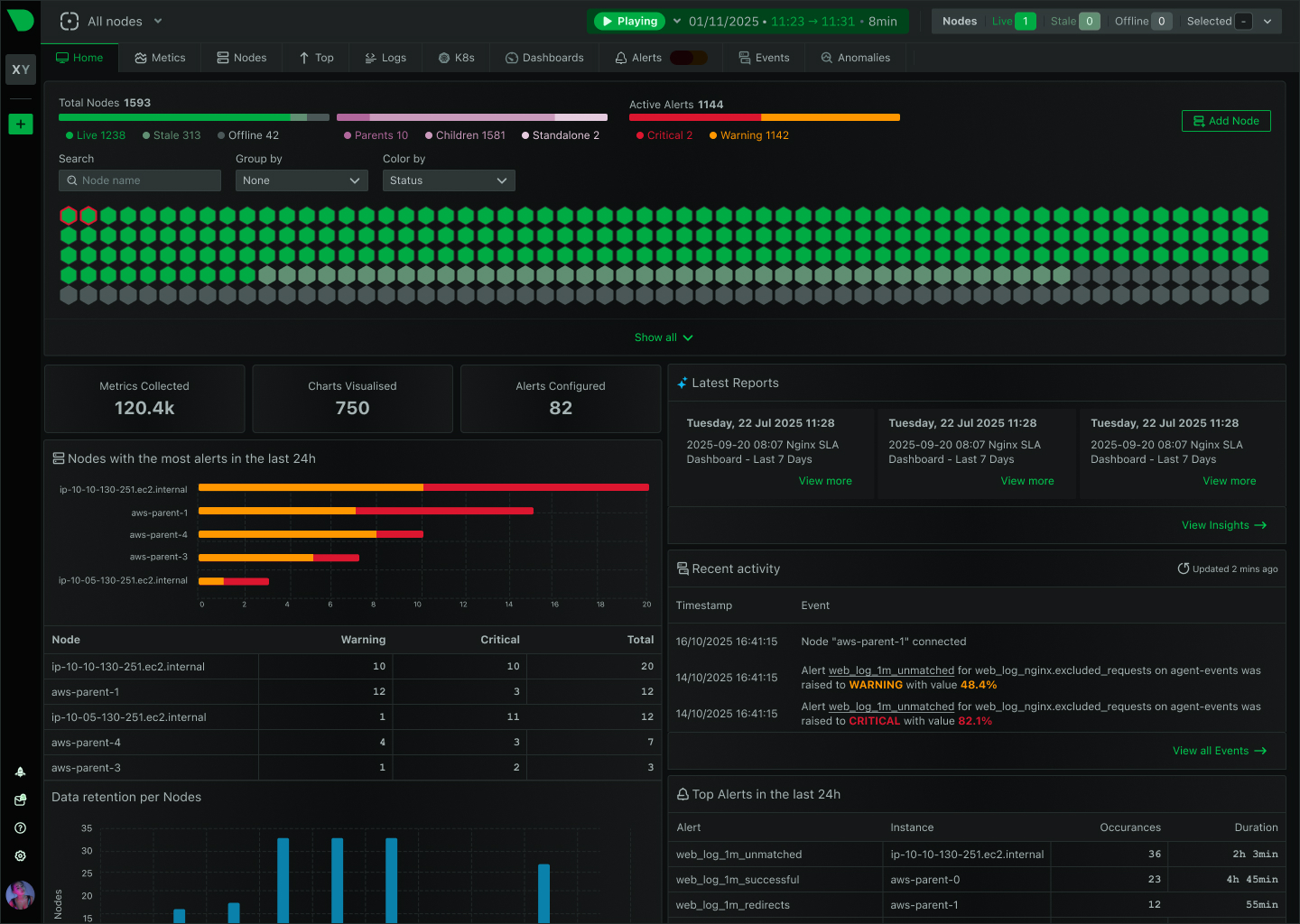
Track failures across 100,000+ nodes in real-time
See distributed architecture
99% false positive reduction in anomaly detection
Learn about ML accuracy
2-minute AI reports vs hours of manual investigation
Explore AI Co-Engineer
100% data sovereignty - metrics never leave your infrastructure
Review security design

How Netdata Transforms RCA
See how Netdata’s edge-native architecture and ML-powered correlation fundamentally change root cause analysis - from hours of manual investigation to seconds of automated insight.
Capability
Netdata
Traditional Monitoring
Detection Speed
✅ Real-Time
Anomalies detected during data collection
⚠️ Delayed
Batch processing with minutes of lag
Data Granularity
✅ Per-Second
86,400 samples per day per metric
⚠️ Per-Minute
Misses 90% of transient events
ML Accuracy
✅ 18-Model Consensus
99% false positive reduction in anomaly detection
⚠️ Single-Model
Higher false positive rates
Correlation Speed
✅ Seconds
Evaluates thousands of metrics instantly
❌ Manual
Hours of dashboard review required
Root Cause Surfacing
✅ Top 30-50 Results
Automated ranking by relevance
❌ Manual Search
Engineers hunt through dashboards
AI Explanations
✅ 2-Minute Reports
Complete RCA with evidence
⚠️ Limited
Pattern matching without causality
Configuration Required
✅ Minimal
Auto-discovery and automated dashboards
❌ Extensive
Weeks of dashboard building
Average MTTR
✅ 5 Minutes
80% reduction from baseline
❌ 75+ Minutes
82% of companies exceed 1 hour
Cost Model
✅ Per-Node
Predictable, unlimited metrics/logs/users
❌ Volume-Based
Unpredictable, scales with data
Data Sovereignty
✅ Complete
All metrics stay on-premises
⚠️ Limited
Telemetry shipped to vendor
18 ML models per metric detect problems as they happen during data collection - no batch processing delays. Consensus-based flagging achieves 99% false positive reduction in anomaly detection while unsupervised learning adapts to your infrastructure's unique patterns.
15 minutes to first ML detection after installation
Learn about ML accuracyEssential features that transform incident response from reactive firefighting to proactive problem-solving
Capture transient failures that 30-second monitoring misses entirely - see the 3-second events that break systems.
99% false positive reduction in anomaly detection through ensemble learning that adapts to your infrastructure.
Evaluate thousands of metrics in seconds - root cause surfaces in top 30-50 results automatically.
Complete RCA reports in 2 minutes with hypothesis, evidence, and recommendations in plain English.
Watch failures propagate in real-time - identify which component failed first versus downstream effects.
See all affected components instantly - understand full incident impact across distributed infrastructure.
Logs, metrics, and alerts correlated automatically - no manual timestamp matching required.
All metrics stay on-premises - only metadata to Cloud for unified dashboards and compliance.
Per-node pricing eliminates volume anxiety - unlimited metrics, logs, users at 90% lower cost.
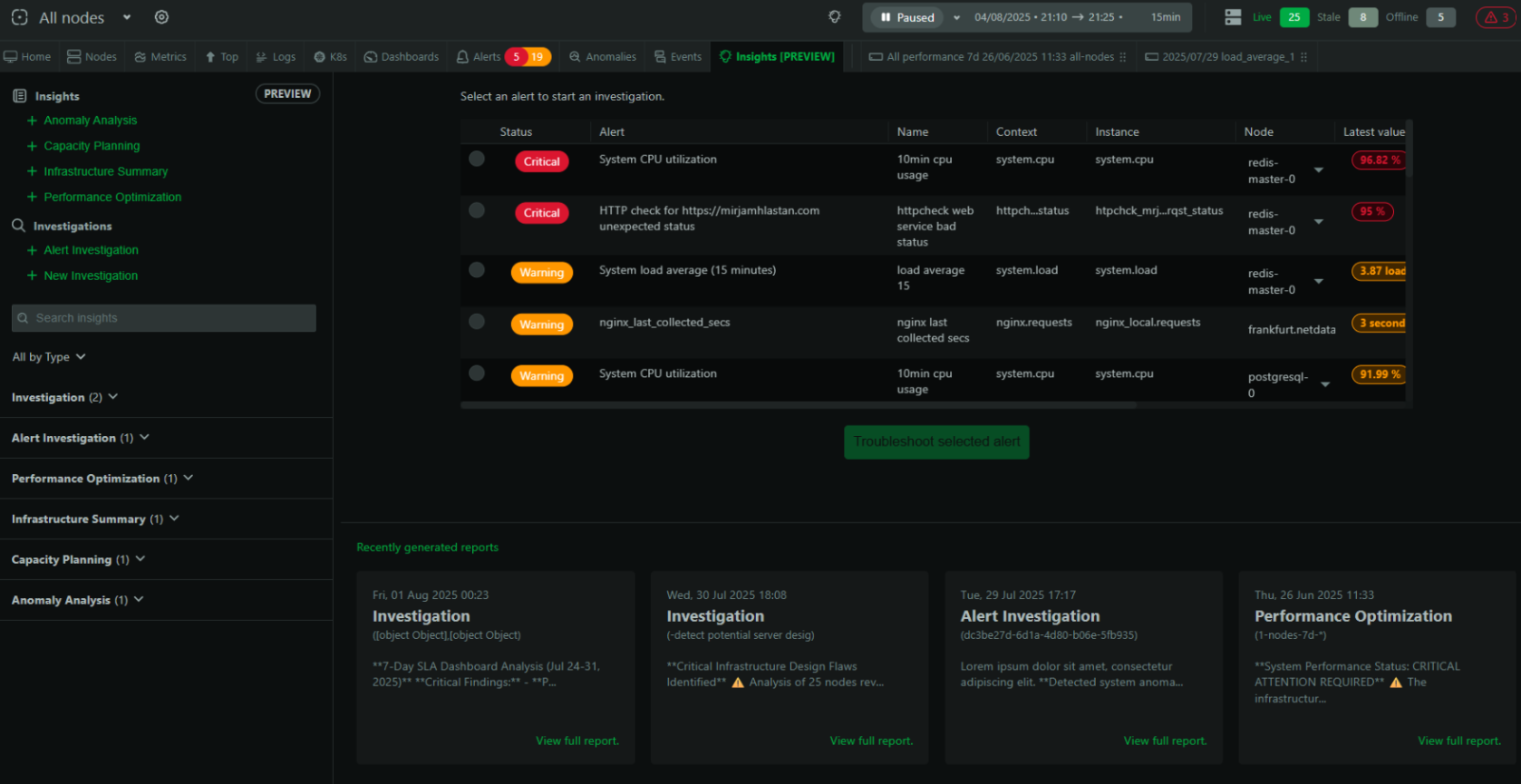
August 3, 2025
Introducing Automated Alert Troubleshooting - Netdata AI: Your Co-SRE that performs initial investigations, identifies root causes, and eliminates alert fatigue.
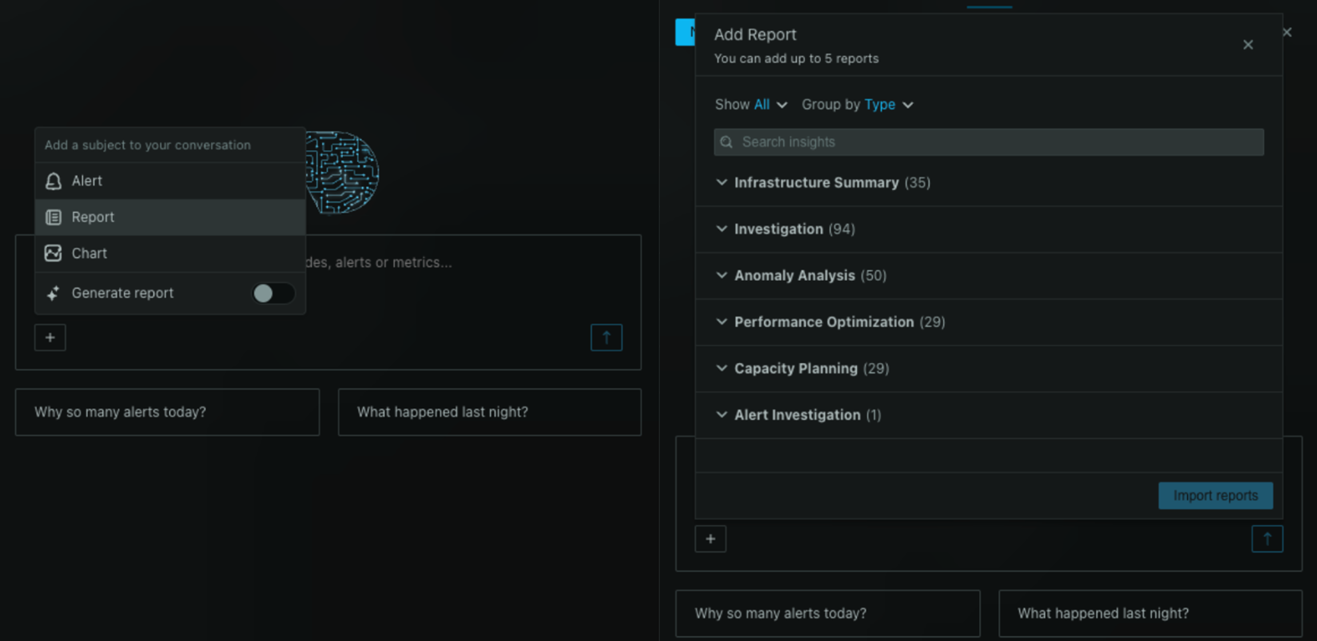
April 2, 2026
Netdata AI now lets you start a conversation about any chart, alert, or Insights report directly from where you're already working. Ask questions, get explanations, and kick off deep-dive investigations without switching context.

February 27, 2026
Connect AI coding agents like Claude Code, Codex, and Cursor to your entire infrastructure with a single endpoint. The Netdata Cloud MCP Server brings infrastructure-wide observability to any MCP-compatible AI tool.