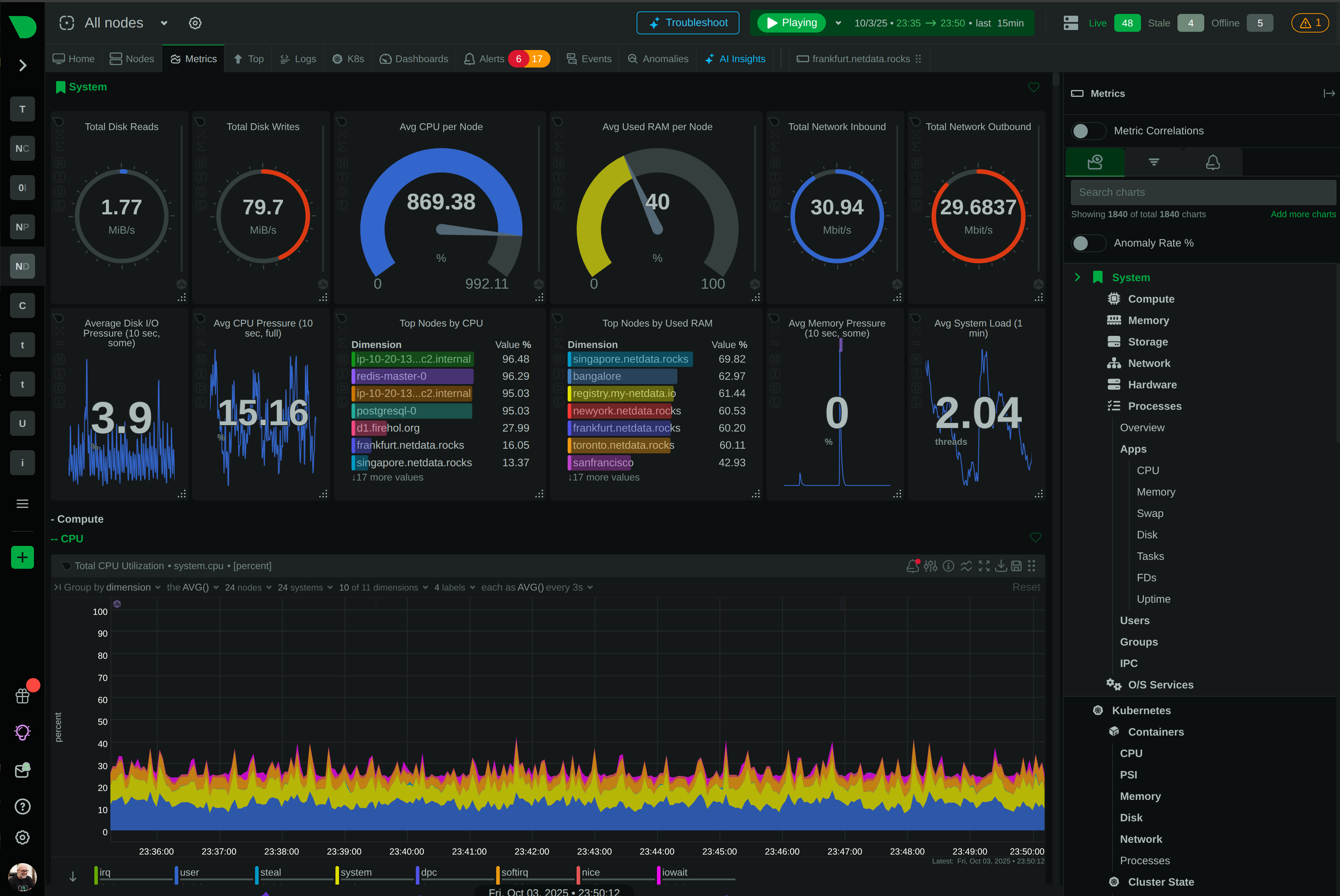
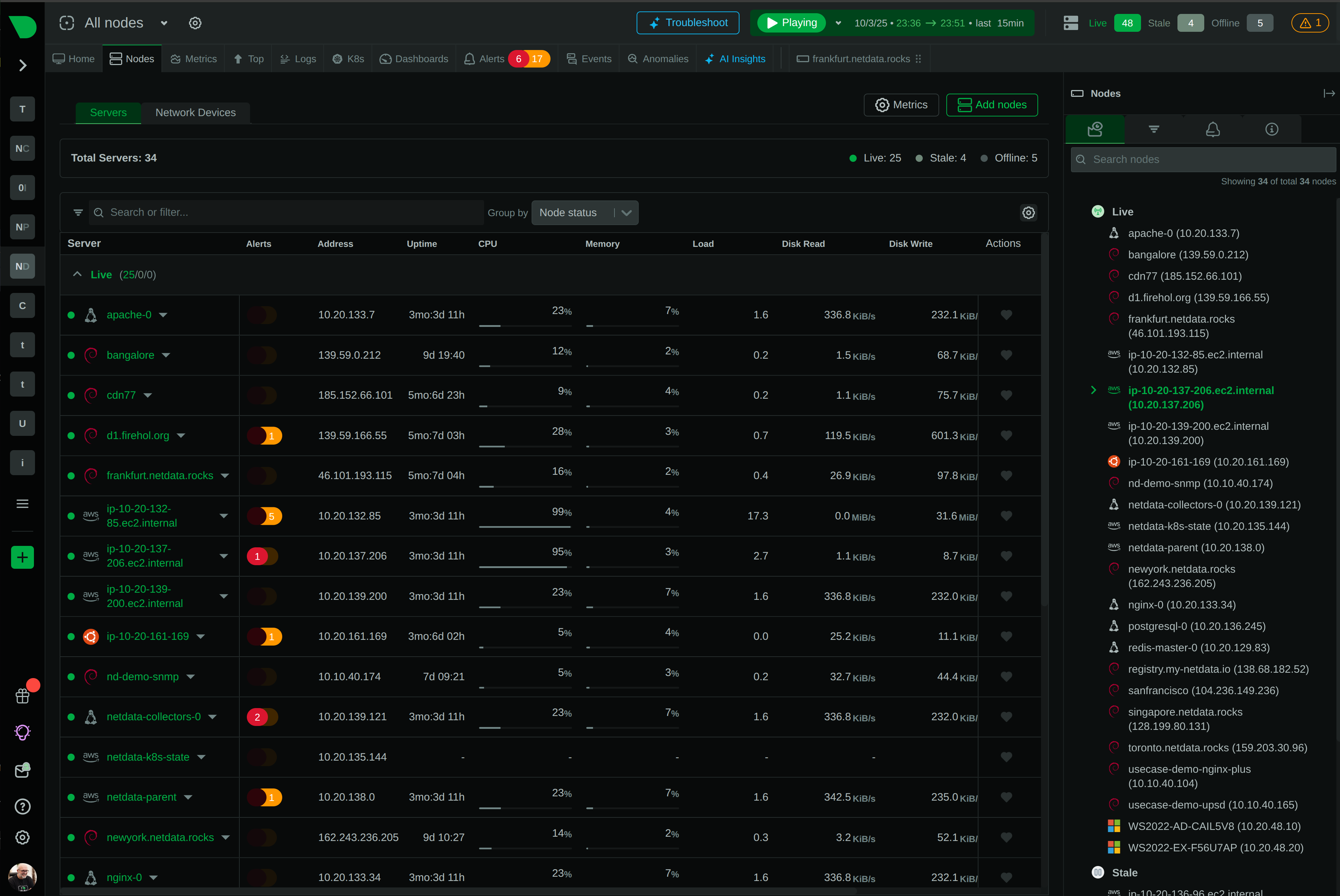
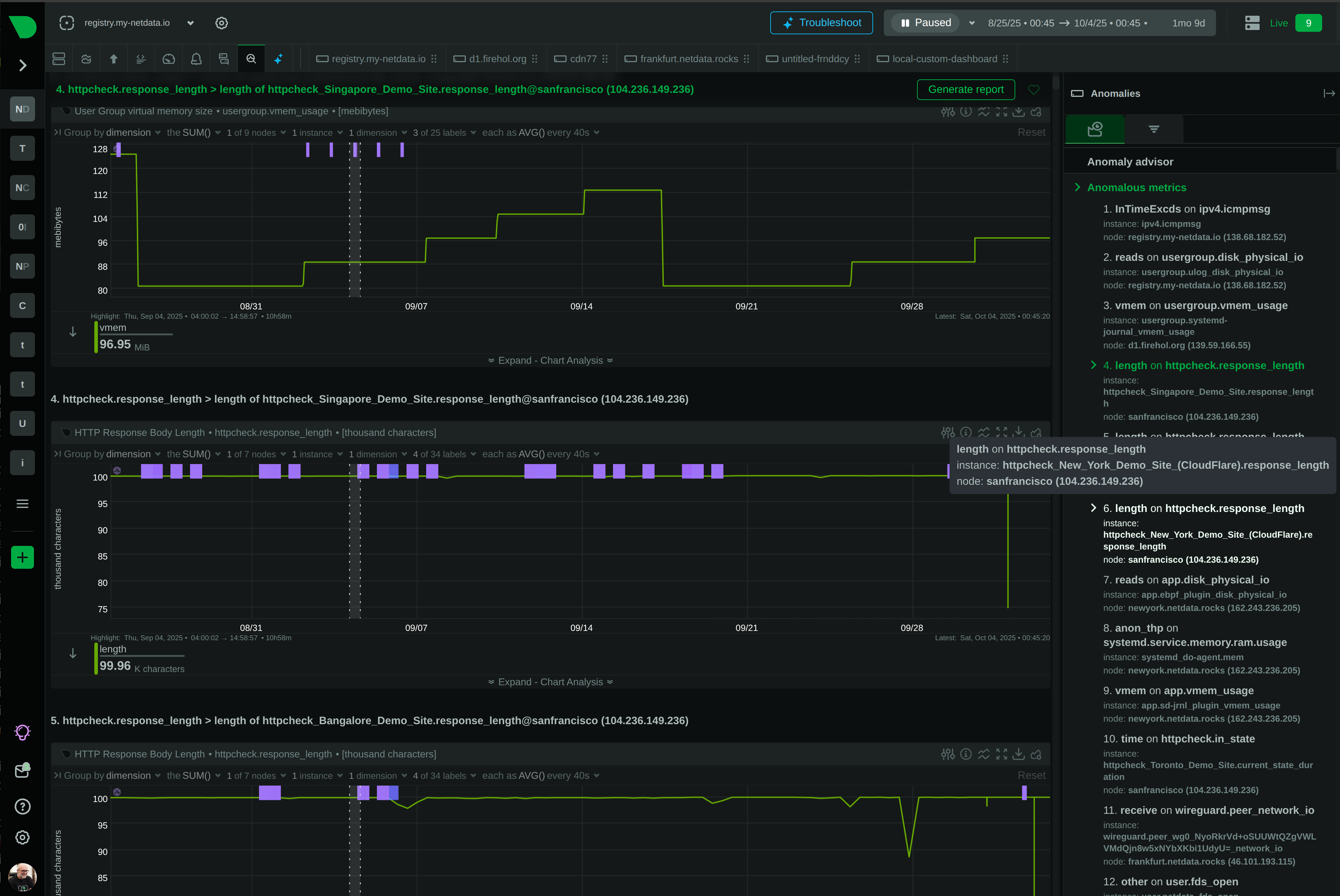
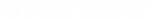Conversations with teams switching off Datadog converge on the same three reasons. None of them are about capability.
First, the bill model. Per-host plus separate meters for custom metrics, log ingest, log indexing, APM, RUM, and synthetics. Each meter grows independently with workload, and the renewal estimate that arrives doesn’t look like the contract’s base rate. Teams who love Datadog have budget headroom; teams who leave have run out of it.
Second, cardinality pressure. Custom-metric pricing forces teams to drop labels they actually need — the user_id, the pod_uid, the request_id that would have explained which customer/instance/request was affected. The label discipline becomes a quarterly ritual. Then a customer escalation requires the label you dropped.
Third, the SaaS-only constraint. Datadog has no self-host option. For data-sovereignty workloads — regulated industries, EU operations, on-prem deployments — Datadog is structurally not the answer. Teams in this category leave for Netdata, Grafana, or Prometheus depending on operating-model preference.
The next sections compare Netdata against Datadog directly on each of these axes.